The Semantic Layer landscape, what you need to know before choosing one.
TLDR;
- Why this article: The semantic layer vendor space is crowded, the marketing is near-identical, and no existing analysis goes deep enough to actually inform a procurement decision. This article does, with the added credibility of someone who built one.
- Most important take: The governance vs. flexibility is the decision you're making, not the feature checklist. Every vendor resolves it differently, BI-native tools (Power BI, Looker) lock you in but govern tightly; headless layers (Cube) give API flexibility at operational cost; warehouse-native (Snowflake, Databricks) have zero infrastructure overhead, but you surrender your AI roadmap to the vendor. The architectural question underneath all of it: Is this vendor selling you a definition system or a description system? Only the former actually solves the problem.
- A challenging thought: Every vendor demos on clean tables. Nobody demos on a schema mid-migration. The hardest question to ask, and in my opinion, the one that exposes whether their semantic layer is what they say it is, is this: When a table definition changes, how long does it take for that change to propagate consistently to every AI-generated query, every dashboard, and every scheduled report? If the answer involves manual steps, a separate pipeline, or "it depends", you have your answer about how serious the claim actually is.
Text-2-sql isn't actually the point.
The real question for agentic analytics is not "can AI write SQL", is whether people can do things they couldn't do before, and if users are moving meaningfully faster. Framed this way, the semantic layer stops being a technical implementation detail and becomes a capability the system relies on. Without it, you don't get a slower product, you get wrong answers produced at scale, and for any organization that would be worse than no answers at all.
This article has been three months in the making. The timing could not be better; it lands between two major conferences in the semantic layer space (two weeks ago Cube's Agentic Analytics Summit, sessions are up on YouTube , and next week AtScale Semantic Layer Summit).
If you are a Chief Data / Analytics Officer evaluating vendors, and oh boy, the space is getting crowded, your real concern should not be a feature checklist, rather what organizational changes will each vendor will force on you, which bets are reversible, and what decisions will define your AI stack for the years to come.
The marketing is near-identical; the architectural differences, however, paint quite a different picture. So far, I have not seen an article that goes deep enough to actually inform a procurement decision. So, I wrote one.
I will be transparent, though, I built semantido , which is still a work in progress with a major version update coming up, and the reason I did so will be clear by the end of this article. The experience I gained by actually building one gives me a unique insight into going beyond the marketing surface. The repo is available on GitHub, and don't expect a collection of Markdown files :) which seems to be the 10k star GitHub repos these days ... but I digress.
Why this decision has more consequences than it looks.
Semantic layers rarely make headlines the way new model releases or Claude Code skills do. They have, however, quietly become one of the most important infrastructure decisions in enterprise data, and vendors are starting to sense this opportunity.
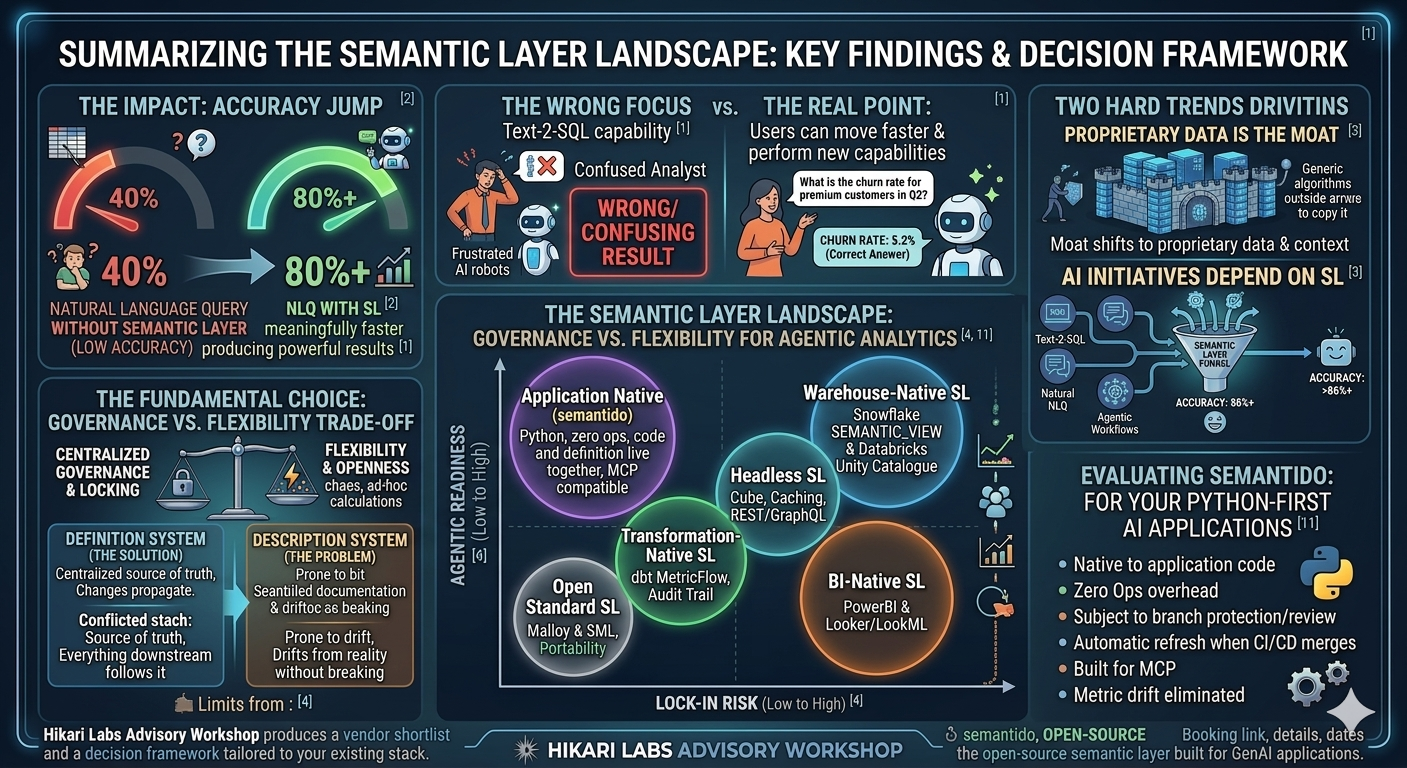
Natural language query accuracy without a semantic layer sits around 40%. With one, it jumps to 80% or more. Snowflake Cortex, Databricks Genie AI, and Google's own research, all arrive at the same numbers within margins of error. I validated a similar number on a fitness analytics pipeline, with roughly 30% baseline accuracy on a gpt-4o model, rising to 90% once a semantic layer was in place. To give you an estimate, there were approximately 16 tables across three schemas with one-one, one-many relationships including bridge tables. So, not really a simple toy schema you usually see in most of the tutorials on the internet.
The 40% gap is not a tuning problem. It's not something a better model would fix, or if you want to wild a more carefully engineered prompt. This is an infrastructure problem, and the decision you make now will be one of the most important data architecture choices you will make in 2026.
The two hard trends driving the need for a semantic layer adoption:
-
As software becomes cheaper to produce (and we can argue around this, but bear in mind I am in the camp of the AI realists), your competitive moat shifts to proprietary data, distribution and customer context and trust. Mark Cuban framed this well, and the logic holds regardless of where you sit on the AI adoption curve.
-
Every major analytics initiative, be that text-2-sql, natural language, or agentic data workflows, will depend on a functional semantic layer supporting both retrieval and generation accuracy.
As I said in previous articles, semantic layers are not new. If we are to look a decade ago, we see that LookML has been around 2012, Cube launched in 2019, dbt's metric layer existed in a form or another from 2021. What changed in 2024 is that AI put the semantic layer as a core dependency of every analytics initiative, and by doing so, exposed a tension that always existed but rarely mattered enough to make a decision.
So, what the conundrum is then you might ask, in my mind is a governance vs. flexibility trade-off observed in many years of doing data work.
Centralize and lock the definitions, and nobody will use it since it won't accommodate what they actually need to track. Open it up and you end up with 10 definitions of the same term. Cube named this tension directly at their Agentic Analytics Summit: their answer is a SQL-first semantic layer that lets AI construct ad-hoc calculations on top of governed metrics, preserving both sides. It is a thoughtful answer. It is however not the only answer. And understanding which answer will fit your organization is exactly what is article is for.
The vendor landscape
For this article I asked our friendly sycophant Claude to do a small analysis on the vendors in this space. I did double-check it, it also told me I have great ideas at every step, so it must be true sarcastically speaking. One thing I liked, though, was the way they were categorized and will go with it and structure this part of the article accordingly.
There are 6 categories of vendors in this space, each representing a different architecture, vendor relationship, and organizational constrains. They are plotted in the picture below across two dividers, the lock-in risk versus agentic readiness. The bigger the bubble, the larger the vendor lock-in risk. The higher on the chart, the better the position for an agentic system to interact with it.

Category 1: BI-Native semantic layers (Power BI/ Microsoft Fabric, LookML / Looker)
This is, by far is the oldest category, and where a semantic layer has existed even before we would call it this way.
Power BI’s semantic model (called "dataset", rebranded in 2023) is the most deployed semantic layer in the enterprise today. It predates the "GenAI era" by more than a decade. Built on DAX, for metric definitions and Power Query for data transformation. Every measure and relationship is defined in a Power BI semantic model, which is in effect a governed semantic definition, although it was not called that way.
Microsoft Fabric strategy elevates the semantic model from a Power BI feature to an enterprise data infrastructure. Copilot in Fabric uses the semantic model as its "business language layer"; the same DAX definitions that power your Power BI dashboards can now answer natural language queries from business users. The AI integration seems native, not retrofitted (this is an educated guess as I cannot confirm it). For organizations already running on Microsoft 365, Azure, and Power BI this is a compelling, low-friction, path to AI-native analytics.
The constrains:
- DAX is a powerful language, but it's Microsoft proprietary
- XMLA endpoints allow external tools to query the semantic model. However, as mentioned above, the definitions themselves are Power BI objects, and they do not transfer cleanly to any non-Microsoft system, and of course you have to be "premium" to use some of its advanced features.
Vendor questions:
- If you need a "copilot" for anything agentic, then you have your answer right there. Is Copilot scope matching your agentic ambitions?
- If you want an "agentic system" to construct ad-hoc queries beyond what's defined in Power BI’s semantic model, how would that work? And by that, I mean exploratory analytics (Power BI models are a curated, human-defined set of measures and dimensions, with other words limited to what they actually expose). In fairness, most enterprise BI use cases don't hit this wall, as they are purposely designed for a specific task, however, if your AI analytics ambitions go beyond that, which is precisely the positioning of agentic analytics.
LookML is the other major BI-native player and built around a similar premise, buy into the Looker ecosystem and get a governed semantic layer as a part of the package. Similar to Power BI Looker was designed for human analytics through the Looker interface, not LLMs through an API. Definitions are accessible via Looker's own query execution layer.
In many facets Looker is similar to Power BI The honest comparison between them, both carry the same fundamental constraint, semantic definitions are owned by the vendor ecosystem, NOT your organization, with the highest lock-in risk of all 6 categories.
Category 2: Headless semantic layers (Cube)
I would say the main issue for BI-Native Semantic layer would be the coupling between the tool and the semantic layer itself. This is what Cube solved for, its API first, exposing the semantic definitions via REST and GraphQL. Cube's innovation in this field is its caching and pre-aggregation engine. Semantically defined metrics are materialized at query time for sub-second responses. This is a strong advantage when UI latency is a constrain for agentic workflows.
The tradeoff however, is running a service, with all the architectural Illy-ties that come with it. Cube schema language is its own (similar to the approach in Category 1), thus your knowledge encoded in the semantic layer will be around Cube's abstractions.
I personally took it only for a test drive. I was impressed by its capabilities (and here I would make clear this is the open-source version of it). Overall, it has less of a lock-in than Power BI and Looker, but it’s fundamentally a piece of infrastructure your data team would be comfortable to manage.
Category 3: Transformation-native semantic layers (dbt MetricFlow)
The path dbt took is fundamentally different. Rather than building a new layer on top of the warehouse, dbt extended its transformation workflows to include metric definitions alongside table transformations. A change in table definitions is a pull-request, with all the good parts of it (a reviewer, test, and history). Metric definitions live alongside git, providing a defined audit trail on what and when changed. For regulated industries this is not nice-to-have; it’s a must.
From a licensing perspective, dbt MetricFlow is Apache 2.0., meaning there is no licensing risk to the core semantic layer capability.
This, however, only works if dbt is your transformation backbone. Anything that bypasses dbt models, and consequently, MetricFlow will not have any references to. This goes in the same line with Power BI, whereby ad-hoc questions without a "semantic model" attached to them would not work.
Category 4: Warehouse-native semantic layers (Snowflake, Databricks)
Let's talk big boys now. Snowflake and Databricks made the same architectural bet, the semantic layer should stay inside the data warehouse and not as an external tooling. Snowflake introduced SEMANTIC_VIEW () constructs and Databricks integrated metric definitions into Unity Catalogue.
The case for a warehouse native semantic layer is simple, zero additional infrastructure, and deep integration with existing governance layers (automatic lineage, ownership, and data quality).
The case against is pure lock-in. Similar to Power BI, Snowflake semantic view definitions are Snowflake objects. They do not transfer to other warehouses. For organizations running multi-warehouse or multi-cloud, it’s a bet with a very long tail. Now there is one more angle to it, if they live in the warehouse, then the vendor effectively controls the roadmap for your AI capabilities and begs the question if you are okay with this from a procurement perspective.
Category 5: Open Standard semantic layer (Malloy, AtScale)
This category packs the vendors making the bet on portability as a primary strategic value, not features or ecosystem depth, rather the guarantee that your semantic definitions will go beyond any individual vendor relationship.
Funny enough, Malloy was created by the two original authors of LookML (Lloyd Tabb and Michael Toy), which is also funny enough I met them in New York at one of Oreilly Conferences maybe 2012–2013. If only I knew, I would have handed them some cash there and then when they were advertising at the startup panel. Malloy unifies what LookML got wrong, i.e., the split between the model definition and query writing. In Malloy, you define your semantic model and query in the same syntax. This way you get cleaner LLM generation because of the easiness of the language model to "understand" Malloy. For organizations investing in agentic AI systems that would write their own queries, this is a non-trivial property.
The tradeoff is adoption cost and Malloy language; however, I will see it as a serious contender for greenfield agentic data, and would be quite a hard sell for existing BI systems' migration.
AtScale's Semantic Modeling Language takes a different approach to portability. Rather than introducing a new query language, as Malloy does, SML is an open-source YAML specification, designed as a superset of the existing semantic modeling languages: LookML, MetricFlow, Power BI model definitions, and MDX. AtScale's ambition is to become the portable interchange format for semantic definition across the entire vendor landscape, the same way Parquet became the interchange format for columnar data.
SML offers a migration path that does not require re-building your existing definitions. An organization moving from LookML to a Gen-AI native architecture could, in principle, translate LookML definitions to SML and then consume them through any SML compatible tool. Time will tell whether this portability holds in practice, but the architectural intent of definitions owned by the organization and not the vendor is the right intent.
Category 6: Application native semantic layers (semantido)
Now my own take to the whole semantic world. Semantido occupies a position in this landscape that has no direct equivalent among other vendors. Every vendor mentioned above operates at one of three layers: BI tool, transformation pipeline, data service, or the warehouse layer. All of them treat the semantic layer as a separate system.
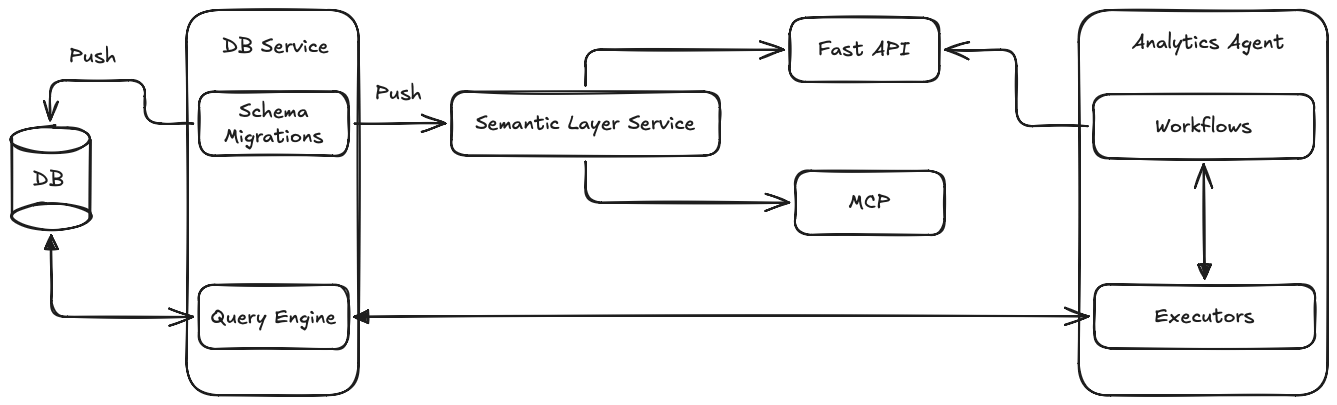
Semantido treats the semantic layer as part of the application itself. In my many years of data engineering, I realized that the tables themselves would paint only a part of the picture, the application itself has a semantic meaning as well. Rather than introducing a new service, semantido extends existing SQL Alchemy models, the python ORM than most of the Python data applications already use, with semantic decorators. The table definition and the semantic definition of that table live in the same file. A metric is not a separate YAML file in a different repository, it's a decorated python method on the SQL Alchemy class it belongs to.
For organizations where primary data consumers are python applications, Fast API backends, agentic systems making data queries, MCP servers exposing data via tools, semantido means ZERO additional operational overhead. No services to scale, no dbt pipeline to trigger, no warehouse semantic view to version. The semantic definitions deploy with the application because they are part of the application.
For regulated environments, the governance model is different. Because semantic definitions are essentially Python code, they live in the same repository as the application code, subject to the same code-review process, same branch protections, and they are automatically refreshed when the CI/CD pipeline merges then. This feature makes semantido unique, there would never be a metric drift as the semantic generations will be automatically built when any of the underlying tables change.
For the elephant in the room, the MCP. semantido's definitions can serialize its definitions into an MCP compatible format. This would natively give agents access to contextualized data schemas rather than raw table structure. semantido was built for the MCP and agentic world; semantic definitions are python objects with rich metadata exposed via different interfaces, well suited for MCP serialization or context enrichment.
A 10.000 feet architecture of how semantido fits in agentic analytics is shown below
There are constraints, though.
- semantido does not provide any caching, for sub-second dashboard queries this is not a good fit.
- semantido does not integrate with BI tools like Looker and Tableau. Although the open semantic layer might be a way to do it, the library does not have that capability yet.
- semantido is python native by design, for data teams operating in JavaScript, Scala, or warehouse SQL-native environments this would be a less optimal fit.
The frame for evaluating semantido is not "does this replace our semantic layer?", for most organizations it does not. The frame would be: "as we build Python-first AI analytics capabilities, does it make sense for the semantic layer governing those capabilities to live in the same codebase and the same operational model?" For teams building agentic systems, the answer is increasingly yes.
The comparison at a glance
| Power BI / Fabric | LookML | Cube | dbt MetricFlow | Snowflake / Databricks | Malloy / AtScale SML | semantido | |
|---|---|---|---|---|---|---|---|
| Primary consumer | Human analyst + Copilot | Human analyst | Any (API-first) | dbt pipeline | Warehouse AI layer | LLM / any tool | LLM / Python agent |
| Semantic language | DAX | LookML | JS/TS schema | YAML MetricFlow | SQL / warehouse DSL | Malloy / YAML SML | Python decorators |
| Deployment | Microsoft Fabric | Looker-hosted | Self-hosted or cloud | dbt project | Warehouse-native | Language / OSS format | In-application |
| Operational overhead | Low (managed) | Low (managed) | High (service) | Medium (pipeline) | None | Low–medium | None |
| Warehouse lock-in | Medium (Azure preferred) | Low | None | None | High | None | None |
| BI tool lock-in | High (Microsoft) | High (Looker) | None | None | Vendor-dependent | None | None |
| GenAI / MCP readiness | Native (Copilot/Fabric) | Retrofitted | Good | Good | Native (Cortex/Genie) | Good (Malloy esp.) | Native |
| Governance model | Power BI endorsement | Looker IDE | Git + Cube Cloud | Git (pull requests) | Warehouse governance | Git / open standard | Git (same repo as app) |
| Pre-agg / caching | Yes (import mode) | Yes (Looker) | Yes (core strength) | No | Yes (warehouse) | No | No |
| Open source | No | No | Core yes | Yes (Apache 2.0) | No | Yes (both) | Yes |
| Best fit | Microsoft / Azure orgs | Looker shops | Headless BI teams | dbt-first teams | Single-warehouse orgs | Greenfield / portability | Python-first / agentic |
Closing thoughts
The question no vendor will answer for you, so I am.
Every vendor or contender in this space will demonstrate their product working well on a clean demo database with four tables and unambiguous column names. But this does not hold in any real scenario. When building semantido, I have faced an issue that many data teams do. When changing table definitions and even schemas, how to update the definition of, say, "active customer". How long does it take for that change to propagate consistently to every AI-generated query, every dashboard, and every scheduled report? This is in essence semantido philosophy and promise, change once, and this propagates seamlessly.
For the CDOs, the answer to the above question tells you whether the vendor's semantic layer is a definition system or a description system. A definition system is the source of truth; everything downstream follows it. A description system is a documentation layer, it can drift from reality without breaking anything, and it usually does.
Only definition systems solve the problem. The architectural difference between vendors in this space is, fundamentally, the difference between those two things.
Outro
Next in the CDO series: "AI-ready data – what's this all about?"
Hikari Labs helps data and AI leadership teams evaluate and implement semantic layer architecture for GenAI applications. If you are planning this decision for 2026, the advisory workshop is a two-hour structured conversation that produces a vendor shortlist and a decision framework tailored to your existing stack. Book here.*
Subscribe to my newsletter to stay up to date with the latest articles and open-source projects.
Disclaimer:
- This article is a personal reflection of my own experiences and opinions and does not represent any of my employer(s) views.
- AI was used in grammar correcting this article and to structure a vendor comparison. I care about my readers and respect their time.
- Some of the images used in this article have been generated with Gemini 3 Pro, based on the article text given in the prompt. Others are made with Excalidraw by yours truly.
- semantido , the open-source semantic layer built for GenAI applications, is available on GitHub.