What is a semantic layer after all?
TLDR;
In case you only have 1 minute, here is the very, very short version:
- Why this article: The term "semantic layer" has been overloaded by marketing teams (ironically, given that semantics literally means "the study of meaning") and will attempt to disambiguate that. LLMs learn meaning through statistical patterns in training data, but struggle with business-specific contexts and tabular data where relationships aren't explicit.
- Order of operations: Semantics must come before ontology. First define what something means in a specific context, then build the ontology.
- A funny analogy I came up with: Think of semantics as "high-tech glasses" for vision-impaired LLMs. Without explicit semantic context (especially for tabular data like SQL), models hallucinate as they can't "see" relationships that weren't in their training data. RAG helps with text, but structured data needs explicit semantic layers.
- My most important take from Dave's the book extended to AI Agents and Workflows: Semantics isn't just about words – it's about whether applications (and now AI agents) understand and agree on what information means in the real world. This is critical for agentic AI workflows.
- A challenging thought: I would argue that one of the reasons the model would hallucinate is that it doesn't "understand" the mapping between its training and what it's asked to do in the context provided to it in a user interaction. Remember that is nothing else than weights and biases ... thus no matter how low the probability, an answer would always be possible.
- The new World: A unified view I propose in this article: We treat application semantics as both application logic and data. By separating them we lose meaning. A robust semantic layer should surface these relationships through a new LLM ready metadata architecture shown in the picture below. I call this the Semantic Layer Service.
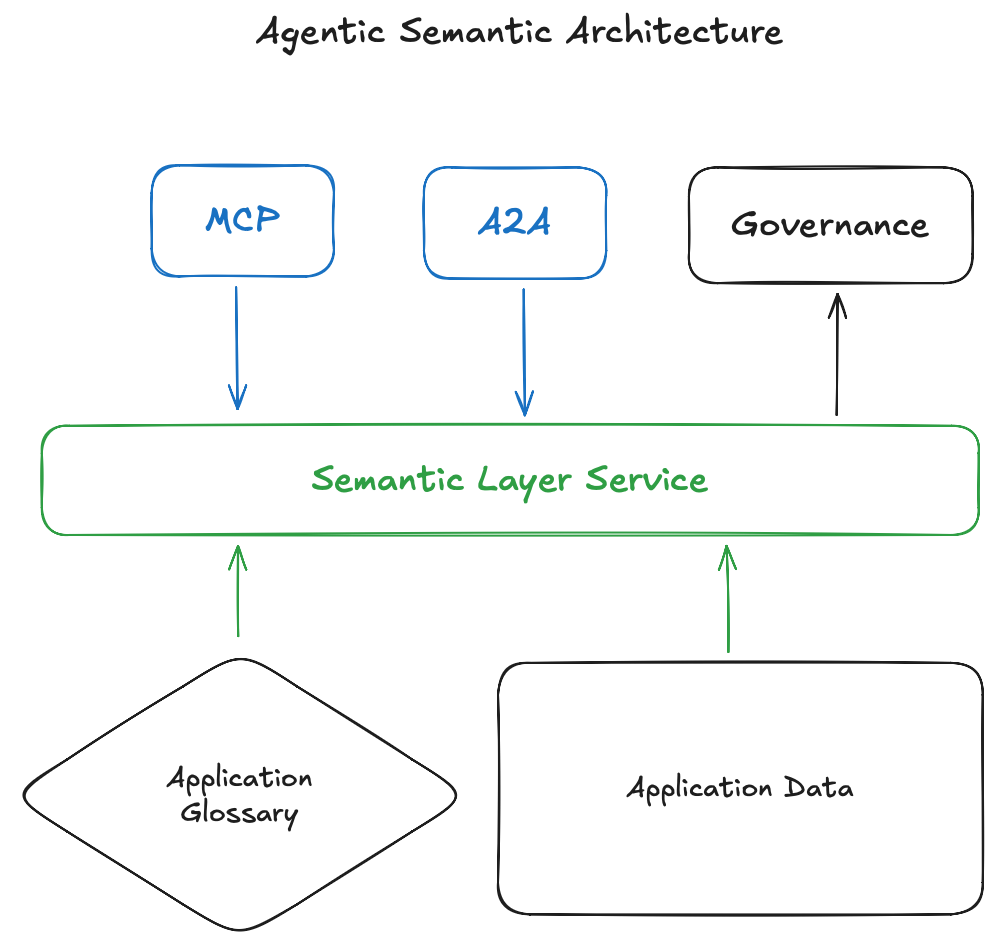
Intro
From a 30.000-feet view, what we know so far:
- GenAI thrives on unstructured and semi-structured data in contrast to traditional systems centered around specific data requirements (tabular data, fixed(ish) schemas, labeled datasets)
- Transformer embeddings are context-dependent, see Illustrated Transformer for an in-depth explanation. This is, unlike earlier methods such as word2vec, which assigned a fixed vector to each word regardless of the context in which it was present.
- GenAI is good by some benchmarks at:
- Natural language understanding and generation
- Content creation (beware of AI slop)
- Multimodal "understanding," i.e., across text, audio, and image.
This article makes the argument that we have overloaded the semantic term (mostly by marketing teams), the most amazing irony of all time in my mind, as the term defines itself as the study of meaning, with "meanings" or things that it wouldn't suppose to do. Thus, we now find ourselves in a conundrum of things. We try to define ontologies first, but meaning later, which again, in my mind it should be the opposite, we first define what a thing "is" in the context is referred to, then we build the ontology graph(s) on top.
I will always use "understanding" in quotes when it comes to LLMs, as this is nothing else than statistical patterns that form meaningful relationships in a vector space, more on this in the article below.
I wrote this article at least seven times. Every time I felt something is missing, something that kept eluding me. Although I have a long history with data engineering and built some quite neat data warehouses, I always advocated the need for a metadata layer.
I did it much from instinct and could not put my finger on why I thought so. Not long ago I found a book called Semantics in Business Systems: The Savvy Manager’s Guide by Dave McComb. After a quick look over the book available on the Internet Archive, I went straight and bough it. And I recommend you do the same if you are serious about semantics. This book was published in 2003, an eternity in ML development times. I reached out to Dave for permission to quote some parts of the book, as this turned exactly to be what eluded me for quite a long time and to wrap the 8th, and final version of this article. The article is my own understanding of the book and how it would apply in the LLM / Agentic world we live in today, so take it with a pinch of salt.
A more recent podcast and reference to the book can be found here Dave McComb: Semantic Modeling for the Data-Centric Enterprise – Episode 29 .
Without further due, let's dive into it and be prepared for a rant!
Semantics, semantics is it like tomato, tomato?
Dave's books kick off with a punchy Chapter 1 Title: Semantics: A trillion-dollar cottage industry. I can only agree that this was true back then as it is today.
In answering the question of why semantics are important, I would like to start by asking first ... How Large Language Models come to "understand" what something "means"?
The (very) short answer is: in the pre-training (aka the main) phase, the bulk of semantic learning occurs through the generation of contextual embeddings (words are linked to the context they occur in). This is followed up by building semantic relationships where the model starts to see that certain transformations in the embedding space correspond to meaningful relationships. What they "learn" is nothing else than statistical patterns that correlate with meaning.
Again, in a (very) simplistic view this is shown in the picture below (we leave out all the cool the transformer/ attention part here, we are focusing on how the embeddings are generated).
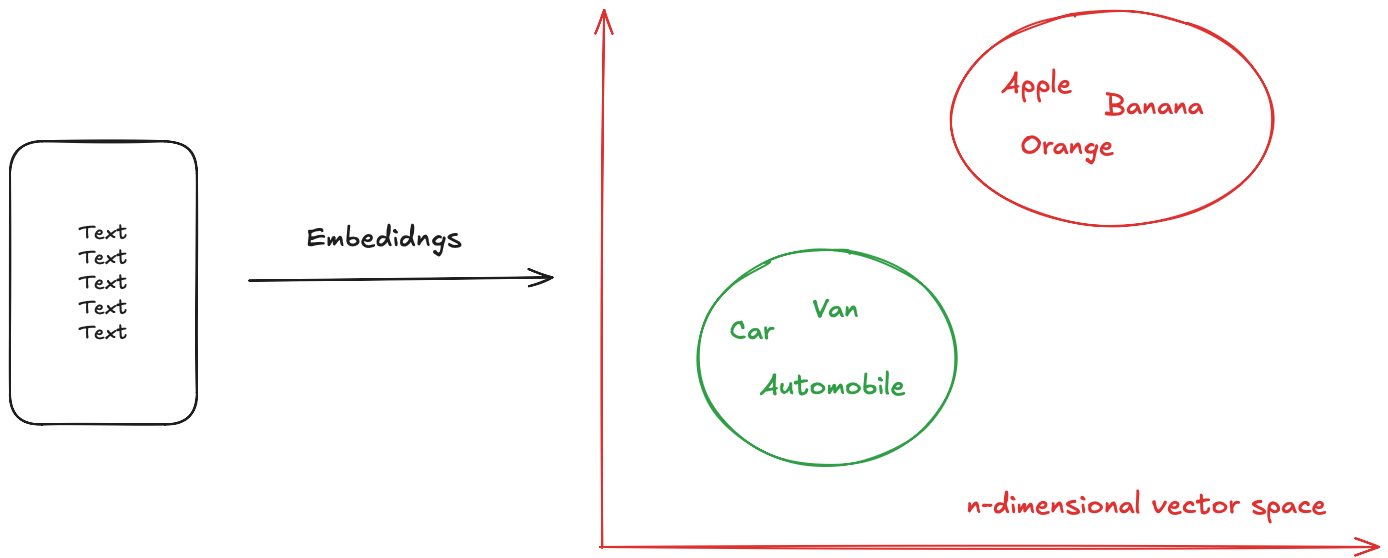
The first issue we would see here is that the semantic relationships are as good as the training the model received. So what's the problem you might rightfully ask. In hindsight, it is clear that if the model was trained on data and relationships that are foreign to your "meaning" of the world, and usually in the business world, this tends to be true, something interesting happens. Unless the "thing" that the business is operating on is not standardized in any form, the language model won't be able to answer you meaningfully, or it would "hallucinate" as it's known in GenAI parlais.
I would argue that one of the reasons the model hallucinates would be that it doesn't "understand" the mapping between its training and what its asked for in the context of a user interaction. Remember this is nothing else than weights and biases ... thus no matter how low the probability an answer would always be possible.
To mitigate this, enter RAG. This technique helps ground the model by providing additional context to something that either wasn't present in its training dataset, or something specific to the business referenced by the user query. For large text corpuses this is "easy," well not quite ... but doable.
Things start to get interesting when we try to work with data that is tabular such as Excel, SQL, or even a table 😊. At this point the model is only partially able to implicitly infer any relationships; it would require that they must be explicitly provided.
The wild roller-coaster ride of GenAI of the past 3 years put more gasoline on an already burning fire. Finding a way to surface this information from relational stores, and maintain the discipline and the agency (no pun intended), to keep it reliable will make a large chunk of being successful when it comes to providing the right semantics in the query context.
And here for the first time, after quite a long description, we come to the word semantics in the context of an LLM retrieving information from a tabular data format. Imagine it like this: you are a Large Language Model, and you seem to have a vision loss and start to hallucinate when you don't "see" an answer to a query. Semantics are the high-tech glasses that help the model "see" and guide it to a correct answer. How is that for an analogy?
Semantics – Definition
Semantics is the study of meaning
Dave's book expands this definition with the following:
Semantics is often defined as the study of the meaning of words, but we are going to take the broader definition here, allowing for the possibility for meaning to reside in something other than just words. Ultimately, the relevance and success of our application systems rest on what the symbols that we are manipulating inside the computer really mean in the "real world." Of importance is not only what they mean – but do the people, and other computer programs, that deal with the presented information understand and agree with the meaning as implied by the system?
This is, in my view, one of the best philosophical takes of meaning in information technology. It already asks if a computer program understands and agrees with what it's presented to it. Given the new Agentic AI era we live in, this is likely to be a part of the holy grail of making them work.
Semantics does not live by itself, it is rather a part of other areas of study. The reason I said in the opening of this article that we must first understand semantics (meaning) of things to build an ontology is the way how they are position with respect to one-another. I am modifying the image present in the book a bit, emphasizing the order and relationship.
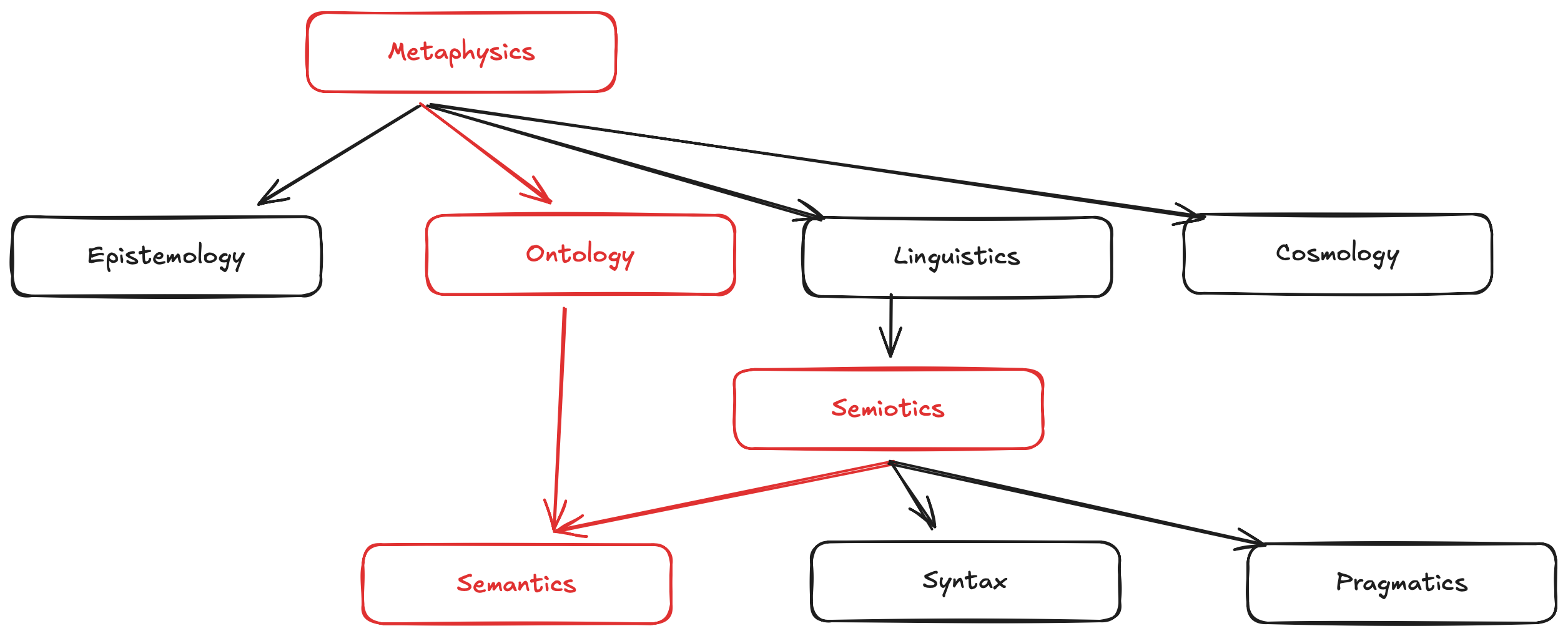
Ontology - is a branch of metaphysics that deals with the structure of systems. Currently, it is associated with organization and classification of knowledge. It is closely related to semantics the primary distinction being that ontology concerns itself with the organization of knowledge once you know what it means. Semantics concerns itself more directly with what something means.
I would make the same claim as the book, albeit in the view of making current models make sense of what they operate on building a semantic layer first is our best hope for the future.
Application, data, and business context
In my opinion, a source system will always be your ground truth, it will contain both the application (i.e. encapsulated business logic) and the data it stores (most likely in tabular form). I believe trying to separate them would contribute to the loss of the meaning on how we would interact with the data produced by the system. I see it like this:
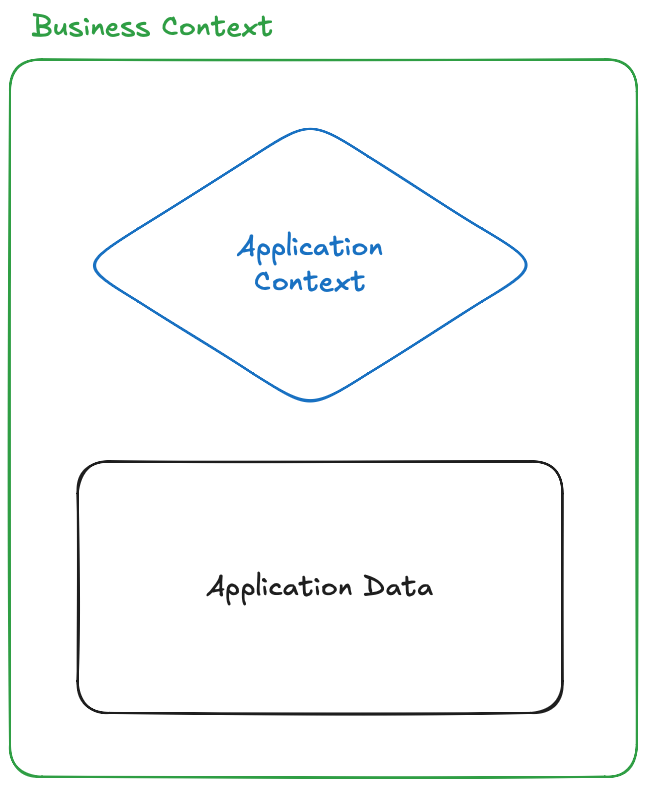
In hindsight, the systems have so far had captured either one or the other without any relationships in between. Surfacing those links, mostly by human insight, or even go as far as training a small model to do it will result in better retrieval and inference when an LLM in an agentic interaction workflow is added to the mix. Keeping this in sync with other data governance systems becomes an easy task. The source system is actually pushing metadata (as a robust semantic layer) as soon as something changes, as a part of its Software Development Cycle - and goodbye stale metadata.
Another gem from the book:
We put words on everything
Then we put meaning on the words
Then we disagree
My take on this is, if a human is not able to reason or understand the system, how would an LLM in an agentic interaction would?
Humans, Applications, and the AI Agentic Bonanza
When an application designer/developer builds an application, he or she "bakes in" a certain amount of semantic knowledge. When the designer/developer decides to have a field in the inventory system to maintain average cost per item, we say that the application has now this semantic. Users of this system don't get the opportunity to redefine this. They communicate with other users at this level of granularity.
The last part of this article brings together what we discussed above in the view of AI. At this point in time, I am not sure if I this is a glimpse in the future in the book. Let's see the sematic flow depicted in the book bellow, original book Figure 3.2 Semantic Interpretation and origination, modified to add Agentic AI as an Application.
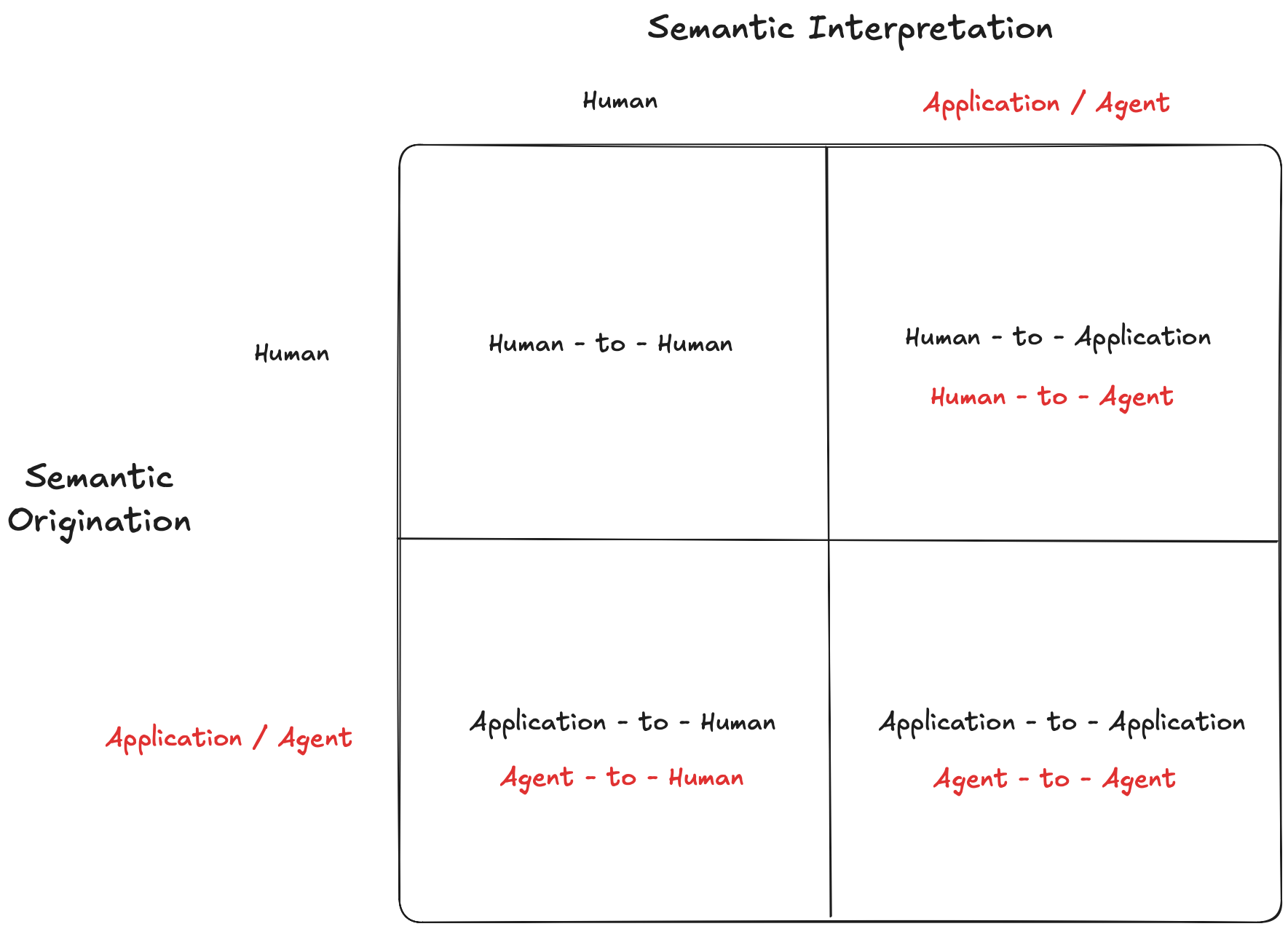
Semantic origination refers to the case in which either the human or an application system is aware of the semantics of messages it produces.
Semantic interpretation means that the recipient, human, or application is semantically interpreting in the message being sent.
In the pre GenAI era semantic layers have been primarily used in BI tools as pre-defined metrics, and they also have been considered as an optional or nice-to-have feature in the data warehouse. Fast-forward to the current days. Semantic layers are a non-negotiable requirement, and moreover, they provide the context in which an LLM operates.
The most important takeaway, though, is that they require a fundamentally different metadata architecture optimized for LLM consumption.
Outro
In the next article The Semantic Layer landscape, what you need to know before choosing one. will compare and contrast what tools are available to build a semantic layer. Spoiler alert... I am not a big fan of semantic-washing, which is what some of these tools are actually doing.
Subscribe to my newsletter to stay up to date with the latest articles and open-source projects.
Disclaimer:
- This article is a personal reflection of my own experiences and opinions and does not represent any of my employer(s) views.
- No AI was used in writing this article. I care about my readers and respect their time.
- Some of the images used in this article have been generated with Gemini 3 Pro, based on the article text given in the prompt. Others are made with Excalidraw by yours truly
- semantido , the open-source semantic layer built for GenAI applications, is available on GitHub.
References: